Share
The success of the Humanitarian Data Exchange (HDX) platform can be tracked partially through its tremendous growth. Since launching in 2014, HDX has grown over 2175% from 800 to over 18,000 datasets accessed annually by over 1.3 million people worldwide (State of Open Humanitarian Data 2021). How does this growth affect HDX’s goal to make humanitarian data easy to find and use for analysis?
During my time with the Centre as a Strategic Communications Data Fellow, I focused on how notions of trust may positively motivate the sharing and use of high quality data on HDX, especially as the platform scales. I also considered how trust in an organization’s data might be used to fast track the quality assurance (QA) process conducted by the HDX team.
For my analysis, I leveraged existing notions of quality from HDX. These characteristics are related to technical quality (rather than content quality/data accuracy) and include measures of freshness, metadata completeness, and active maintenance. See the ‘Feedback and Future Development’ section for more about this.
After conducting research that included both quantitative analysis of website metrics and qualitative user interviews, I recommended two potential paths forward, one focused on trust and the other on data quality: 1) a “trusted programme” for data contributors; and 2) further work on measuring the trends and impact of the QA process itself.
This project was especially exciting for me as someone who has worked on product communications strategies, large-scale online communities, and dataset quality research. What better way to bring these experiences together than to think through how trust can impact dataset quality in an online community of practitioners?
Three Actors, Three Challenges
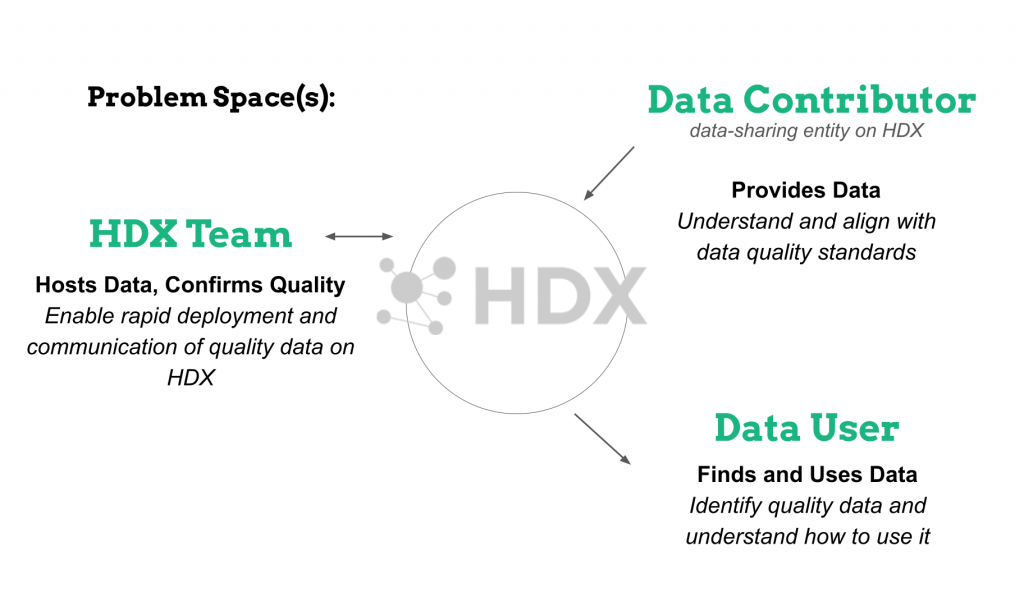
To begin, I explored the relationship between three HDX actors: the organizations providing data (data contributor), the team managing and assessing data (HDX team), and the users downloading data for analysis (data user). Each actor faces different challenges around dataset quality.
For example, data contributors need to understand and align with data quality standards and overcome the hurdle of uploading data onto HDX. Data users visit HDX in order to find and use data, so searchability and accessibility matter most to this community. Finally, the HDX team must communicate quality standards to all the actors and validate that new data aligns with those standards.
Insights about Data Contributors
All three actors are concerned with dataset quality, but the data ultimately comes from one group: data contributors. As a result, I narrowed in on the role of data contributors for deeper investigation. There are currently almost 300 formal (e.g., WFP) and informal (e.g., a working group) organizations on the platform. I wanted to understand the types of organizations contributing high quality data and to see whether the HDX team could leverage this knowledge to encourage more organizations to do the same.
My analysis revealed three major insights:
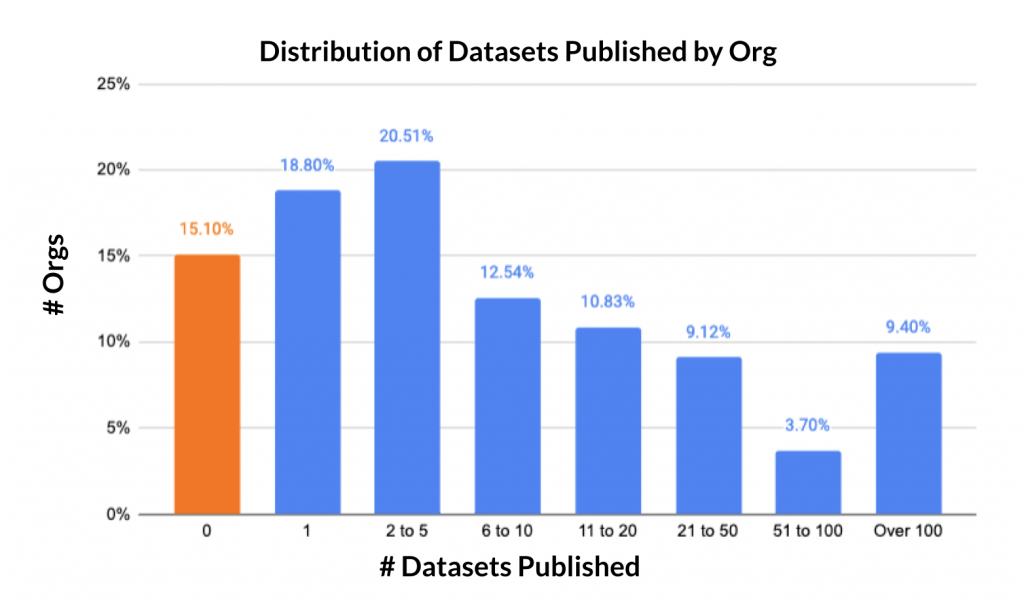
- We are losing potential datasets. 15% of organizations never publish a single dataset after completing the onboarding process.
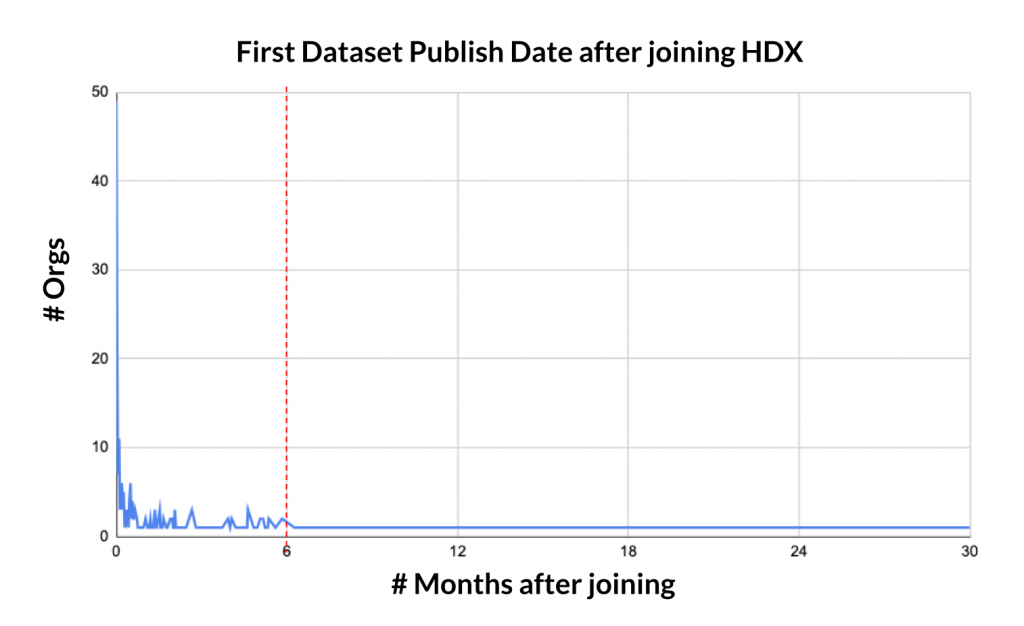
- We have a six-month window of engagement with new organizations. Organizations that do not publish in six months are unlikely to ever publish.
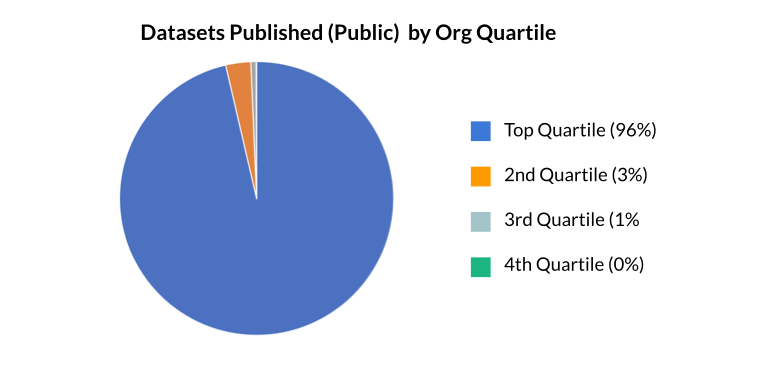
- However, we have very strong ‘power orgs’. Most of the activity on the platform is driven by a small group of active organizations. The top quartile is responsible for 96% of the data published on HDX! (Note that this is not necessarily an indication of quality, but may be a positive indication of engagement.)
Taken together, this presents a two-pronged opportunity to increase data sharing and data quality on the platform:
- Leverage the relationships with the power orgs to build stronger levels of trust through a Premier Organization Programme.
- Adjust the onboarding process for new organizations to incentivize uploading data to the platform, ideally within the first six months.
I wanted to focus on specifically driving higher quality data on HDX, not just more data. Since the ‘power orgs’ are responsible for a majority of the data on HDX, I determined that I would focus on the Premier Organization Programme for the remainder of my fellowship.
Criteria for a Premier Organization Programme
As part of my research, I considered other trust paradigms such as reputation scores (Stack Overflow), verified accounts (Twitter, Instagram), and badges (Reddit) that could be relevant to a Premier Organization Programme on HDX. I explored how such a programme could elevate certain organizations through higher visibility, increased access to resources, and deeper ties with data users and the HDX team.
I sketched out several potential criteria for the programme to understand how these parameters would affect the current data contributor ecosystem. These parameters acted as a proxy for agreed-upon data standards, partner best practices, and community involvement. They include:
- Publishing activity: Org has published >=1 dataset since 2020.
- Active administrator: Org has at least one admin with current contact information.
- Data freshness: Over 75% of datasets in portfolio are updated based on expected cadence.
- Data completeness: Over 75% of datasets in portfolio have complete metadata tags.
Based on these draft criteria, less than 20% of the organizations currently on the platform would qualify as Premier Organizations (65 of the 351). However, this 20% of organizations accounts for almost 50% of the datasets published on HDX, highlighting that there is some positive correlation between power orgs and those that are already following best practices.
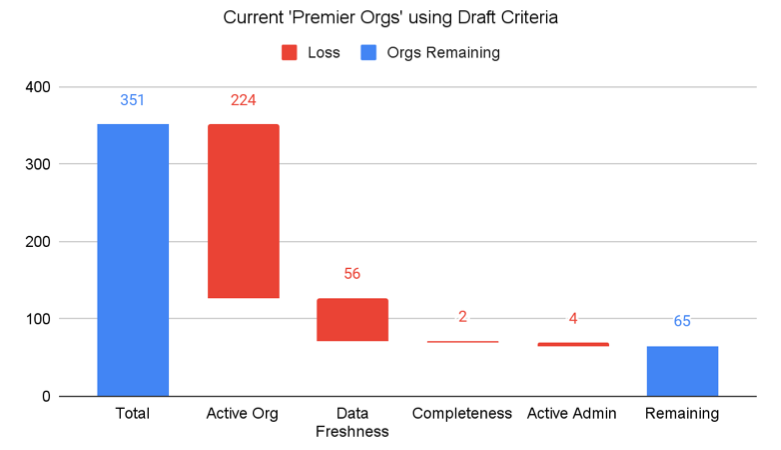
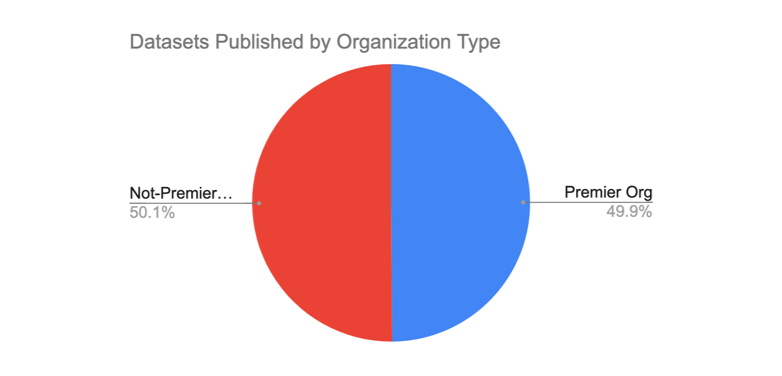
Feedback and Further Development
Through conversations with the team and some select organizations, I was able to solicit initial feedback on the Premier Organization Programme and highlight areas for future development. Everyone was enthusiastic about building a trust-based programme for organizations that are already providing high-quality data on HDX, especially if this includes a community component and opportunities to share learnings across organizations. Furthermore, several people pointed out that a programme that ‘shows what good looks like’ would be motivating for other organizations to learn best practices and improve upon their own methodologies as well, ultimately driving better data on HDX over time.
Next steps for the Premier Organization Programme include identifying a small pilot cohort and working through the components of community, learning opportunities, and what a fast-track QA process might look like.
Differing definitions of ‘quality data’ did come up repeatedly during my research, and with no agreed-upon answer (as of yet!). For the purposes of this fellowship, I decided to define quality as technical quality within the existing HDX framework (data freshness, metadata completeness, and active management of data). However, basic questions about time spent on dataset QA, types of issues encountered, and distribution across dataset types were challenging to answer within the existing metrics system. Thus, building a more robust dataset QA metrics system is another area for further development.
Fellowships are never as long as you want them to be, and this was definitely the case for my time at the Centre! There is still plenty to investigate and validate, from confirming excitement, to identifying pilot organizations, and finalizing the criteria for a premiere programme. However, the foundational analysis certainly supports further exploration. It has been a pleasure working with the team, and I can’t wait to see what happens next!
* * * * *
Learn more about the 2021 Data Fellows Programme and watch the video of the Data Fellows Programme Showcase. The new roles for our 2022 programme will be announced in February or March 2022.