Share
As a Data Science Fellow with the Centre, I explored how HDX metadata tags are used by data contributors and whether a typical user can expect to find the data they are looking for. The goal is for a user to enter a keyword into the search bar and get back a list of all relevant data. If the data has been tagged imprecisely by the contributor, their data may never be found. In this blog, I describe how I analyzed the relatedness of datasets to their tags and developed a solution to improve the tagging of newly added datasets on HDX.
The Humanitarian Data Exchange (HDX) now hosts more than 11,000 datasets shared by hundreds of organizations covering humanitarian crises around the world. As more data is added, it is critical that users are able to find what they are looking for. Keyword search, which relies on user-generated metadata, is the most common way to find specific data on the platform. The use of accurate, relevant tags supports better search results and promotes increased user engagement with data on HDX.
What is a tag?
A tag is a term that a data contributor adds to a dataset’s metadata to describe or categorise the data (and not to be confused with HXL hashtags). Tags can be a single word or combination of words and one or more of them can be added to a dataset when it is uploaded to or edited on the platform. A tag usually refers to a concept or terminology (e.g., health, education, displacement), a type of crisis (e.g., earthquakes, cyclones – hurricanes – typhoons) and/or a specific crisis (e.g., Syria crisis 2011). A search for ‘education’ on HDX will result in approximately 1,400 datasets that have the word in the dataset’s title and/or as one of the dataset’s tags.
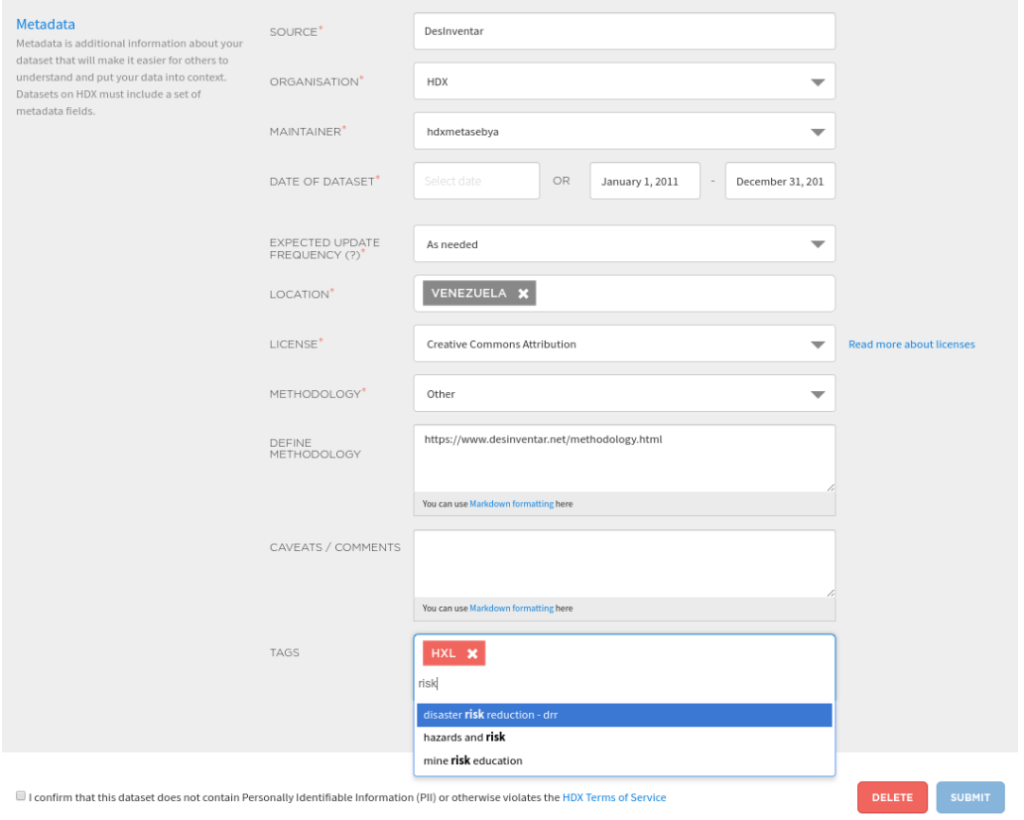
The dataset upload form on HDX has a metadata field where contributors can insert their tags. As of September 2019, there is a fixed tag vocabulary on HDX, a change that was made to improve the platform’s search capabilities. Previously tags were free form, meaning contributors could add whatever words they liked. This led to multiple terms being used to represent the same concept. With controlled tags, once a few letters have been typed, the contributor is prompted with any tags from the vocabulary that contain those letters. The full list of available tags is available here.
The ultimate goal of HDX is to help practitioners and stakeholders find the data they need, but this can be challenging. The HDX team reported that only around 40% of search queries resulted in a download. One reason is that the user may not be satisfied with the result which is likely due to how well datasets are tagged.
Using data science to improve tagging
My fellowship focused on the following two issues:
- Analyzing the relatedness of the datasets on HDX to the platform’s tag vocabulary
- Providing a solution to improve the tagging of newly added HDX datasets
1) Analyzing the relatedness of datasets to tags
Working with the HDX team, I applied data science techniques to select a list of good tags for each HDX dataset using its available metadata. My goal was to build a model that could suggest the most relevant tags for a particular dataset on HDX.
To do this, I had to consider the following points:
- There are many different techniques that can be used for the analysis.
- There is inconsistent use of metadata for datasets, so the amount of information available about each HDX dataset is different. In some datasets, the metadata can ensemble into around 1,000 different words, while other datasets can barely reach 40 words. The challenge is in choosing the important words among the many in the dataset’s content, and then to associate important words with datasets containing a very small number of words.
- Data providers commonly use numbers and special characters or hyperlinks in the description of their dataset. This content usually affects the ability to match with predefined tags and to define similarity in any approach (e.g., “syria crisis-2011” is different from “syria crisis”).
- As the available metadata for each dataset is different, the keyword extraction will also be different, which will affect the data representation.
- As there is no clear pattern in tagging, the number and type of tags used in HDX datasets vary. There is no way to test a model in predicting the current tags if it is trained on only a subset of the HDX datasets and their tags.
- The tags used for HDX datasets that were available for this research before the conversion to a controlled set of tags in September 2019 may refer to the same concept but with different words (e.g., education vs learning; sex/age rate vs demographic; displaced people location vs displacement and shelter). Moreover, the valid list of tags contains more specific concepts (e.g., education in emergencies, education facilities).
- The tags used for HDX datasets can be a variation of the same word (e.g., refugee, refugees).
- Data providers often use acronyms as tags for their datasets. They may use different acronyms to refer to the same concept (e.g., using both ‘3W’ or ‘3Ws’ to refer to a ‘who-is-doing-what-where’ dataset). Or they may use acronyms in a way that will change the meaning and make finding a match in the valid tag list even harder (e.g., using ‘pin’ to mean ‘people in need’).
2) My solution to improve tagging of HDX datasets
I developed a tag suggestion model using a combination of techniques as shown in the diagram below. I evaluated the model by determining a suitable and simple validation metric: the tags on datasets currently in HDX. Then, I tested its ability to retrieve those tags with the goal of improving and tuning the model.
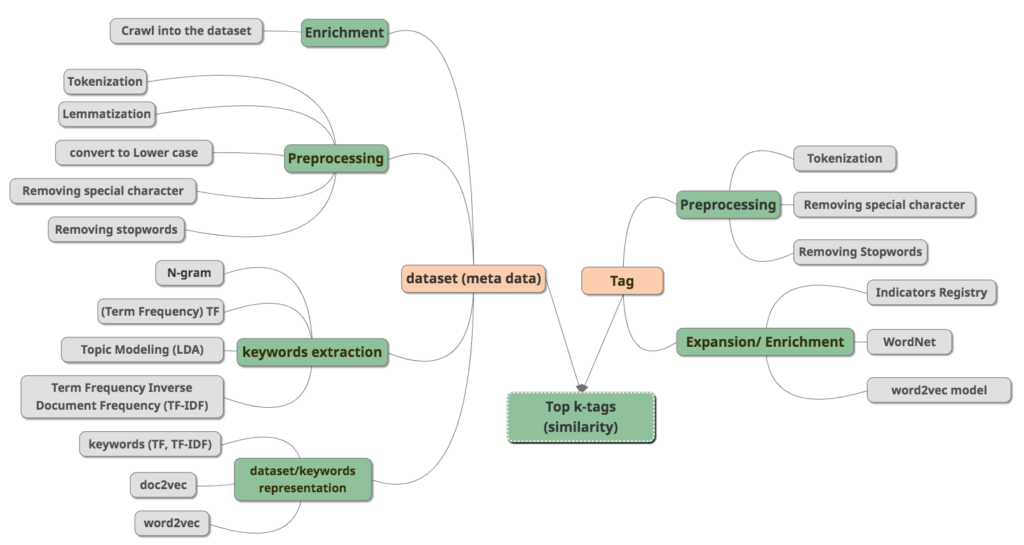
After developing the model, I considered how to improve the tagging process on the HDX platform using this approach. Based on my research and on feedback from the HDX team, I believe this model could be implemented through a tag suggestion module that data contributors would encounter when uploading data.
This tackles the problem of incorrect and insufficient tags by providing suggestions based on relevance. This would also raise HDX user confidence when interacting with the platform in the following ways: the contributor would feel supported in choosing appropriate tags; and an HDX user would have an easier time finding the right data and hence have a more accurate picture of what datasets are available.
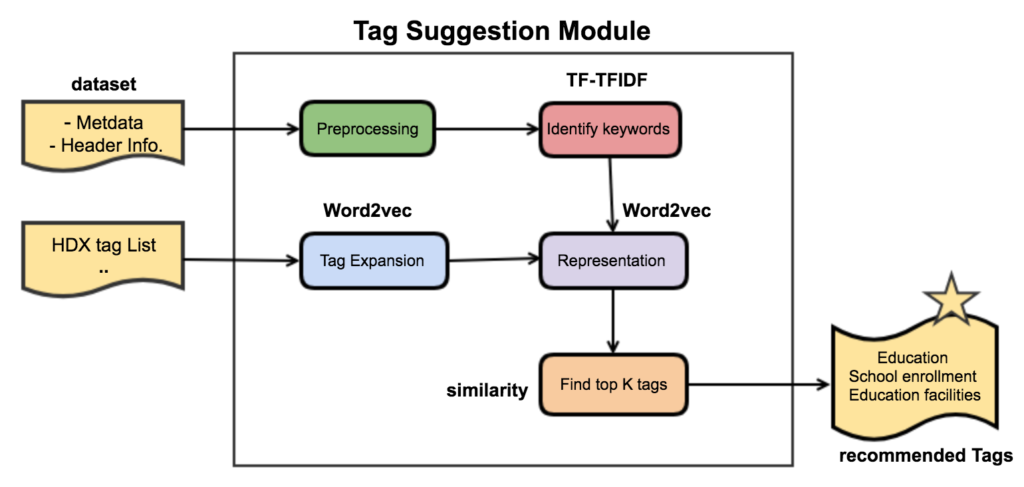
A proposed workflow
The following visuals provide a mock-up of the HDX dataset upload process with the new tag suggestion module. In the first step, the data provider would upload a dataset and provide its metadata. Next, the contributor would be given suitable recommendations for tags from the HDX vocabulary based on the information provided. The set of suggested tags would be shown to the provider ordered by their computed score which shows how strongly a tag is related to the dataset. The contributor would then select one or more of the tags for the dataset.
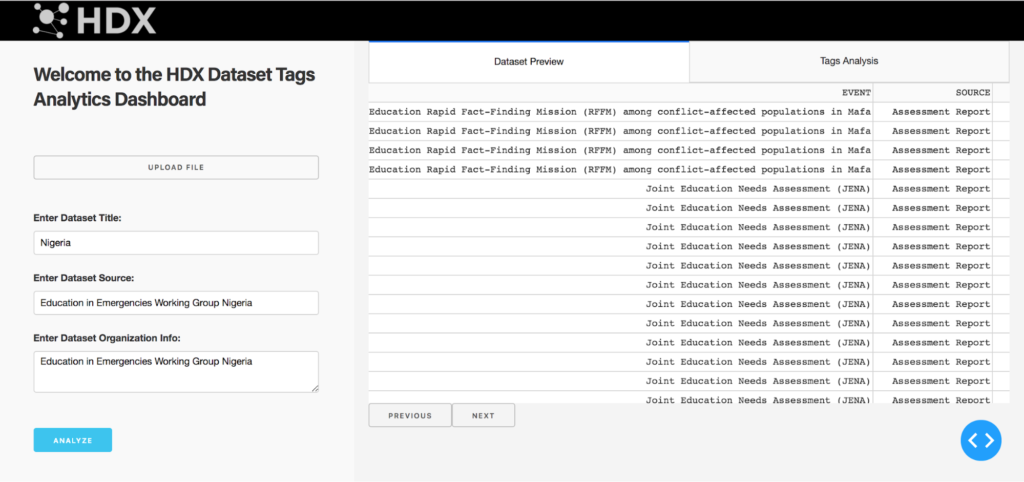
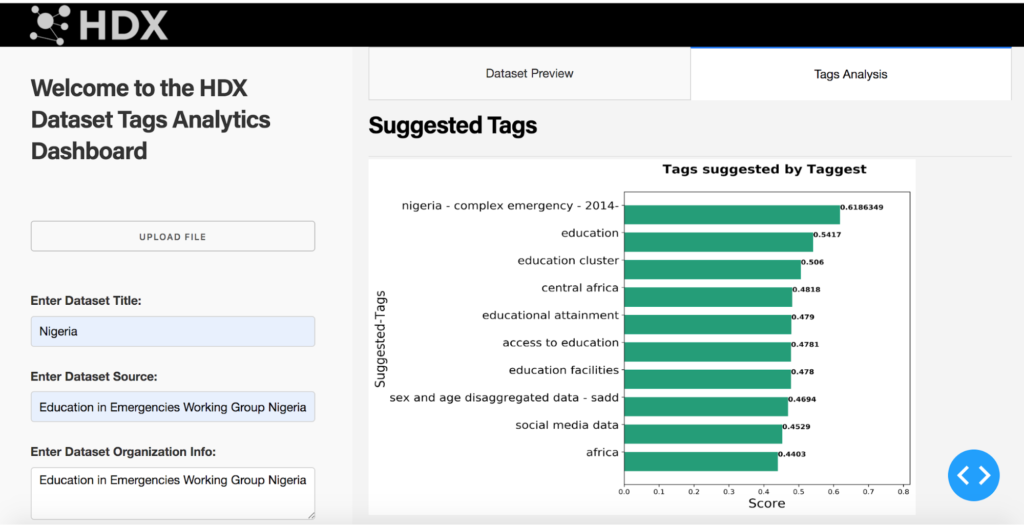
Next steps
The HDX team is working to improve controlled tagging of datasets and will be adding the tag suggestion module to the platform in the future. In the meantime, if you are a data provider, there are a number of ways in which you can help with improved tagging of datasets on HDX. This includes:
- Complete as many metadata fields as possible for your datasets.
- Fill out the dataset description with as much pertinent information as possible.
Watch Ghadeer Abouda present the results of her fellowship on data science at the Centre’s Data Fellows Programme Showcase event in The Hague in July 2019.
The Centre’s Data Fellows Programme is undertaken in partnership with the Education Above All Foundation. Learn more about the 2019 Data Fellows Programme, see video and photos from final presentations at the Data Fellows Programme Showcase, and read about the work from the Programme Lead and Business Strategy, Predictive Analytics, and Statistics (Disability Data) Fellows.








